Decrypting Buzzwords Series, Part 4: Databases

Databases are a keystone of technology that change how the world works. Without them, software today would be next to useless. IPO’s for software companies would be closer to $0 rather than close to the moon.
Understanding databases gives a lens into technologies crucial inner workings, and can help paint a picture of how software actually works.
There are many different types of databases. The one I’m going over in this article is the most common, the Relational Database.
Three main characteristics of a Relational Database are (this is complicated but I’ll explain this next):
Databases allow users to either get information, add information, update information, and delete information easily.
Databases can combine data sets together to allow one set of information to rely on another.
Databases force a particular structure on the data contained within it. This is referred to as a “Database Schema”.
The following story explains these three points, and why the invention of the database was so important.
Back in the 1960s, Coca Cola released three new Coke can designs in Boston. They wanted to use information about the age of their purchasers, to find out if different can designs attract different demographics.
To determine this, they have a month long competition between retailers in Boston. Competing stores can win by selling the most cans overall during the month, the winner gets a free month supply of Coke. Fifty retailers ended up joining in on this contest.
This marketing promotion requires all stores to print out one extra copy of a receipt for Coca Cola, and to write customer information (age of customer and receipt number) on a separate piece of paper to send to Coca Cola. These were mailed to Coke at the end of the month.

The Coke can numbers (1 through 3) were marked accordingly on the receipts. In this way, retailers can enter the competition without much extra effort on their part. They just have to make sure that they write down the general age of a purchaser every time they order a select can, and print out an extra copy of the receipt.
At the end of the month, when Coke received large envelopes and buckets from each of the 50 retailers that entered in Boston, they realized they had a massive issue on their hands. They made life so easy for the retailers, that parsing through all of the information sent was almost impossible!
The oversight here, is that now in order to figure out how many cans of coke are ordered by each individual age group, they need to read the receipt number, find the exact number on one of the many mailed sheets of paper, and then look over at the age group on that row of the piece of paper.
Even for one of the smaller stores with only 1000 orders, that’s still 50 lines per piece of paper, meaning 20 different pieces of paper to sift through to find each individual matching receipt number and then mark down the age!
Larger stores sent whole notebooks full of customer information.
If that was the only issue, they’d be lucky. They may have even been able to honor the competition. Unfortunately, they have one more big problem. In the example above, the age range described is perfect, and exactly what Coke was looking for. 20-25 is easy to understand. Great. However, only 10 out of the 50 stores wrote their customer’s ages down in this manner. Coke never told the Bostonian residents how to appropriately denote age groups, meaning that in most store submissions, the results were almost impossible to understand.
Here’s one example that actually did slightly better than the majority:
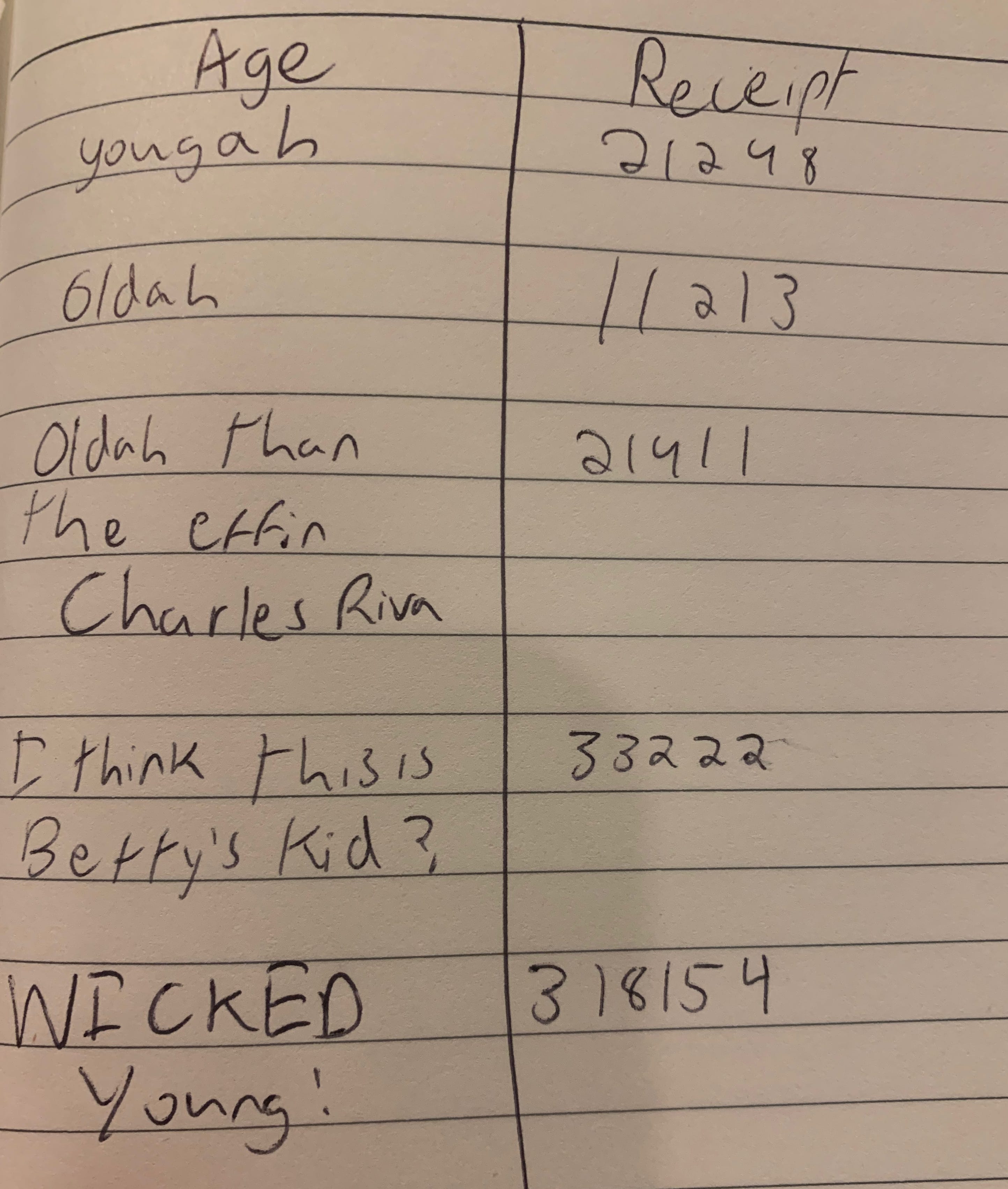
These unexpected results, due to Coke never defining how these numbers should look is the tipping point. They now only have 10 stores with actual good data, but the receipt numbers and piles of paper to go through aren’t worth it. Ultimately, they canceled the competition.
Quick disclaimer, I just made that story up. Even so, how can a database have solved this problem if they existed back in 1960?
To do this, I’m going to list the three main components of a Database, and demonstrate how this problem is easily solvable by leveraging them:
Databases allow users to get information, add information, update information, and delete information.
Instead of having to force retailers to mail Coke large amounts of content inside of envelopes, Coke could today just have a database retailers could connect to. That way, Coca Cola wouldn’t have needed to be mailed anything, and could do all of the necessary calculations within the database.
An API Request could have replaced the mailing of envelopes. It would have saved a lot of trees and a lot of time from having to sift through all of those papers.
Connecting to databases and making data accessible in this manner is done through specific programming languages. The two most common languages used for communicating to a database are SQL (Structured Query Language) and R.Databases can combine data sets together to allow sets of information to rely on another.
A database consists of “Tables”, for example: a receipt table of all purchases, and a customer table of personal information like the customers age.
These pieces of information are related to each other with the concept of a primary key. A primary key is a way to identify a piece of information within a table.
For example, I have two tables; one customer table and one orders table, structured like the way the Coke competition recommended to retailers. The receipts go into the orders table, and the age ranges of the customers go into the customer table. I can then make the receipt number, the primary key inside of the receipt table and customer table. A database allows me to relate these two tables using that primary key. This allows users to analyze both the orders and the customer table using the receipt ID rather than looking through both tables manually.
This would have worked to prevent the visual manual work of finding each receipt number on the corresponding piece of paper, and helped to make this information easily retrievable.
There are three different ways to relate information from one table to another within a relational database. One-to-one, one-to-many, and many-to-many.
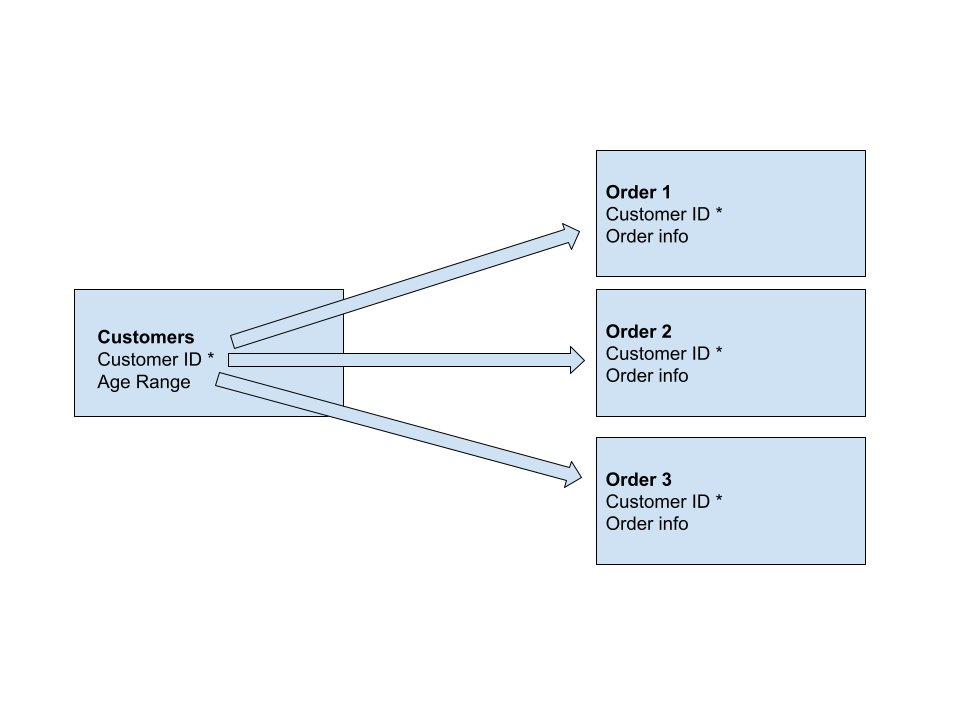
One-to-one: This relationship is described above, every customer only orders once from a store and the order has the customer ID. This is considered a one-to-one relationship because only one customer is related to only one receipt through one primary key.
One-to-many: The above proposed solution wouldn’t be good database design, since one customer can have multiple orders. The proper way of doing this, would be to assign a customer ID and reference on every single receipt. Since one customer can be related to many orders on an order table this can be considered a one-to-many relationship.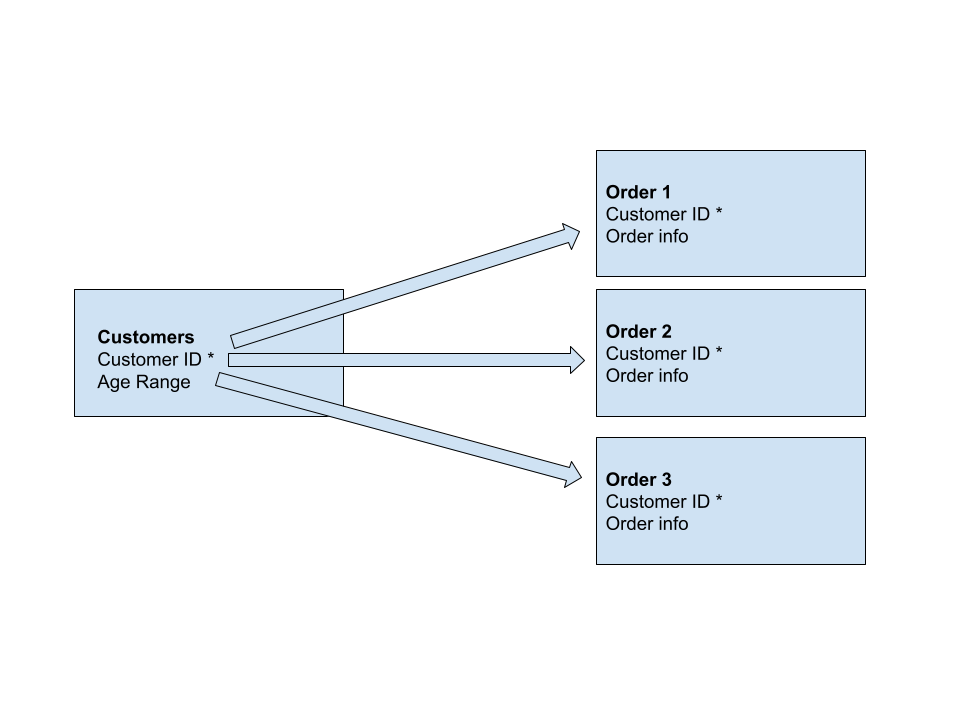
One-to-many relationship, one customer relates to many orders (or receipts)
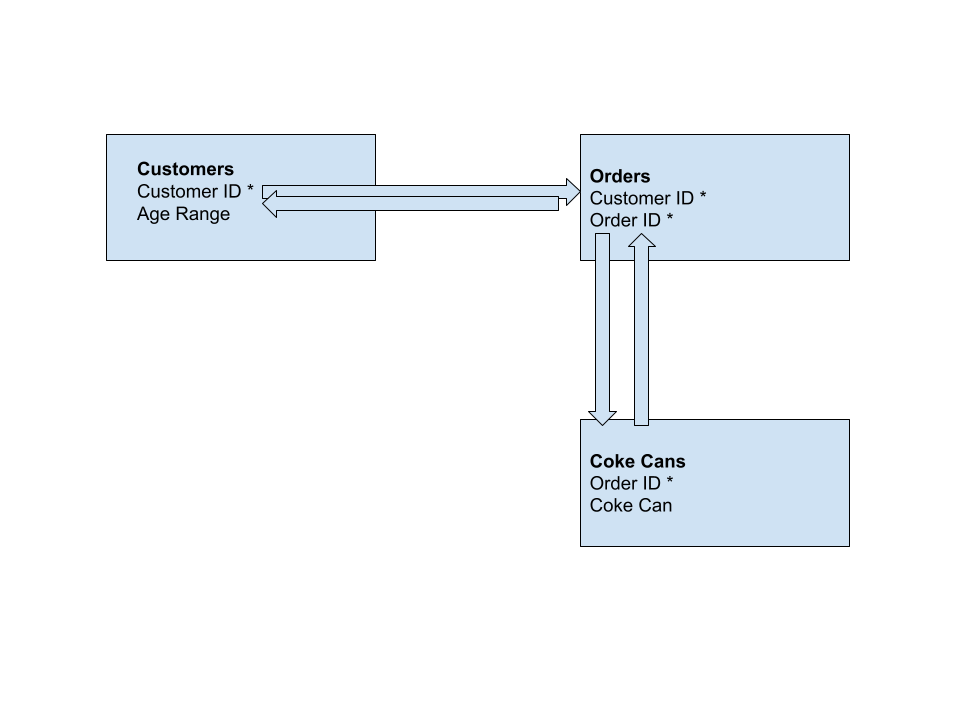
Many-to-many: This is when a table has multiple primary keys that relate to separate tables. To demonstrate this, we’ll need to create a whole separate table for Coke cans that stores the order ID on each receipt, as well information for the coke can.
Then, we’d have to relate the Order ID in our coke table to our order table, and our order table is also saving our customer ID. Thus, our Order table has multiple primary keys relating to multiple tables, one is the Order ID for Coke cans, and the other is the Customer ID for customers. This is an example of a many-to-many relationship.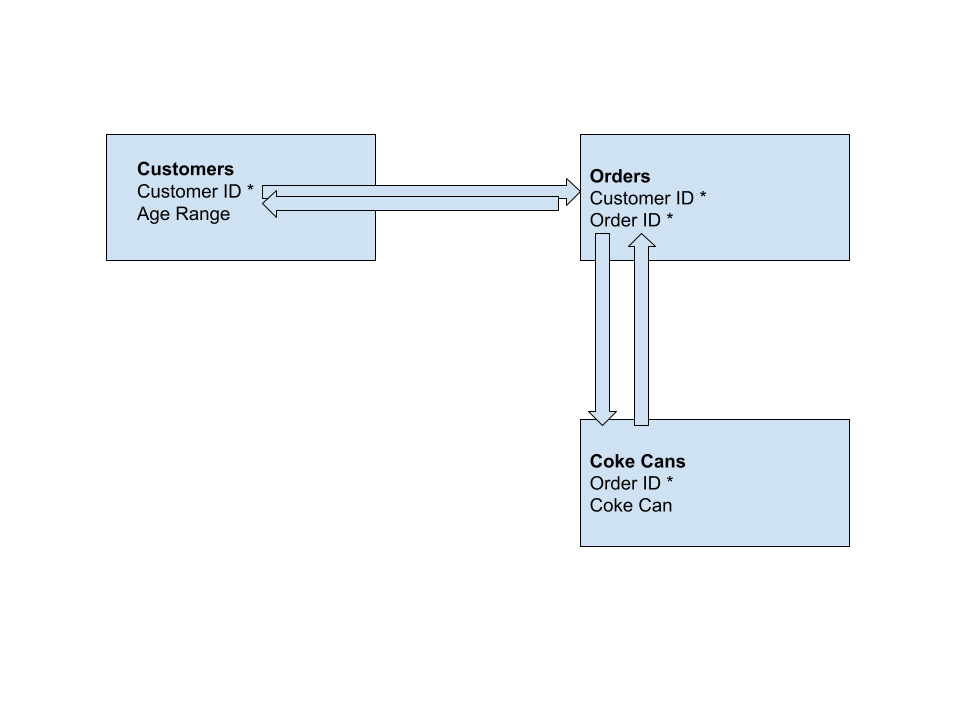
Order Table relates to two tables in two different ways. This symbolizes a many-to-many relationship Databases force a particular structure on the data contained within it. This is referred to as a “Database Schema”.
The problem explained in the image above, where some companies wrote “oldah” whereas some wrote actual date ranges, could have been solved with a Schema.A Schema defines exactly what data should look like when recorded. So, for this example, it would define age as an “integer” meaning that the user needs to put a number down when they fill in age, rather than a word or sentence.
With the three solutions mentioned above, the 1960 Coca Cola problem suddenly becomes easy. The seemingly impossible task of organizing that contest through 50 stores, now becomes very doable.
Scale that outwards, and this once impossible organizational task of analyzing data from only 50 stores, now becomes doable for every store in America. This data is collected by just about every company, and worked on everyday to assist in making important business decisions.
The main takeaways from this article are: that the key components of a Relational Database are
Databases allow data to be accessible by an end user. They can read, append, update, and delete information.
Databases can relate data sets together by referencing primary keys in various ways within other datasets.
Databases require users to define what data should look like before data is saved, to prevent confusion.
Of course, there are many different types of databases, as well as many different technical aspects inside of a Relational Database that I did not cover in this post. Even so, an understanding of the key takeaways mentioned above is enough to conceptualize and even help consult on the construction of databases.